CẦN LÀM GÌ CHO MỘT SẢN PHẨM AI THỰC TẾ?
Nội dung chính
AI (Artifical Intelligence), còn được gọi là trí tuệ nhân tạo, một trong những công nghệ đang được ưa chuộng và phát triển hàng đầu hiện nay, mục đích là để mô phỏng lại quá trình học tập, tư duy và suy nghĩ của con người để cho máy học, đặc biệt là những hệ thống máy tính lớn với khả năng xử lý cao.
Bài viết này mang tính chất gần gũi với việc làm môt bài toán thực tế hơn với các đội dự án hoặc những bạn đang theo đuổi việc làm AI trong thực tế. Đây không phải là một quy trình chung cho tất cả các team nhưng là một quy trình gồm các bước mà Hybrid Technologies nghĩ rằng phù hợp cho một ứng dụng phần mềm có triển khai với AI mà các bạn có thể tham khảo.

1. Hiểu rõ được yêu cầu của bài toán
Đây là một bước rất quan trọng, AI là một lĩnh vực không phải quá mới nhưng không thể thừa nhận rằng khá nhiều người đang hiểu sai về nó. Việc bạn cần phải làm đó là giải thích, phân tích và đưa ra những yêu cầu chính xác giữa mình và khách hàng. Cần phải cân nhắc giữa mức độ khả thi của kĩ thuật và mức độ hiệu quả trên thực tế bởi vì bản chất không có một mô hình AI nào cho độ chính xác tuyệt đối cả. Chúng ta cần phải cam kết được những tỉ lệ (con số) nhất định về độ chính xác của mô hình trước khi bắt tay vào thực hiện một bài toán.
2. Thiết kế hệ thống tổng quan
Đây là một bước rất quan trọng khi làm bất kì một phần mềm nào. Về cơ bản bạn cần phải trả lời được các câu hỏi sau để thiết kế hệ thống cho phù hợp:
- Input/output của hệ thống là gì? Đây chính là câu hỏi mà bạn cần phải trả lời đầu tiên điều đó chứng tỏ bạn đang hiểu rất rõ về yêu cầu của bài toán. Ví dụ đầu vào có thể là một hình ảnh (dạng file) hoặc đường dẫn (URL), hoặc là một chuỗi Base64 được encode. Đầu ra của hệ thống của thể là một JSON chứa kết quả là chữ được nhận dạng trong ảnh đó. Với từng yêu cầu đó chúng ta sẽ thiết kế hệ thống sao cho phù hợp.
- Hệ thống được chạy trên nền tảng nào? Có nhiều bạn ngay từ khi nhận được yêu cầu của bài toán là xây dựng hệ thống nhận diện khuôn mặt đã “lao” ngay vào tìm kiếm dữ liệu rồi training mô hình sao cho đạt kết quả cao nhất. Bạn sử dụng một mạng CNN lên đến mấy chục triệu tham số để đạt được kết quả tốt nhất và có thể đưa vào thực tế dùng ngay. Tuy nhiên đến lúc chạy thực trên Rapsbery Pi thì vừa khởi động chương trình “đơ” luôn cả hệ thống do mô hình quá nặng, chưa nói gì đến dự đoán của tốt hay không? Thế nên bạn cần phải define rõ ràng môi trường để thực hiện và triển khai bài toán. Bạn có thể thực hiện các thí nghiệm với hàng chục GPU khủng nhưng không có nghĩa rằng bạn cũng phải yêu cầu điều đó trên môi trường test.
- Việc cập nhật dữ liệu mới diễn ra như thế nào? Một mô hình AI được làm ra có thể đúng và tốt tại thời điểm hiện tại nhưng không có nghĩa rằng nó sẽ đúng và tốt trong tương lai khi dữ liệu thay đổi liên tục. Vì vậy chúng ta cần phải quan tâm đến việc cập nhất dữ liệu mới như thế nào. Việc cập nhật mô hình khi dữ liệu thay đổi là một bài toán khá dài và chúng ta sẽ bàn sâu hơn trong các phần tiếp theo. Tuy nhiên việc thiết kế hệ thống phải đảm bảo được mô hình AI của bạn luôn luôn đáp ứng được với những dữ liệu cập nhật liên tục.
3. Làm survey các phương pháp thực hiện bài toán
Có một thực trạng của những người mới học hoặc mới làm về AI là quá chú trọng vào việc thử nghiệm các mô hình (model) nhưng lại quên mất một việc mà chúng ta vẫn hay làm từ lúc còn chân ướt chân ráo vào lĩnh vực này đó là tìm kiếm và survey các giải pháp. Kể cả khi bạn đã có kinh nghiệm với các bài toán tương tự thì cũng đừng nên nhảy vào thử nghiệm các mô hình ngay mà hãy nên làm survey các phương pháp để thực hiện vấn đề đó trước.
Lợi ích của việc làm survey
Điều này có một vài các lợi ích như sau:
- Update được công nghệ mới: kể cả khi bạn đã có kinh nghiệm về vấn đề này rất nhiều năm nhưng không có nghĩa rằng phương pháp bạn sử dụng luôn luôn mới. Việc làm các survey bản chất là lục lọi, tìm kiếm tất cả các phương pháp từ mới đến cũ cho bài toán hiện tại nên một lẽ dĩ nhiên bạn sẽ có cơ hội tiếp xúc với các công nghệ mới.
- Có thêm được background về vấn đề: Không ai có thể tự tin rằng mình có đầy đủ background (kiến thức nền tảng) của mọi vấn đề cả, chính từ việc làm survey sẽ giúp cho bạn phải đọc qua rất nhiều paper, rất nhiều blog kĩ thuật rồi từ chúng lại được liên kết với rất nhiều paper hoặc reference khác để giúp bạn lấy thêm các kiến thức.
- Tìm ra được những giải pháp mới: Nếu như bạn đang đi vào trong một lối mòn về công nghệ thì việc làm survey có thể sẽ giúp cho bạn có được những ý tưởng và hướng giải quyết mới cho một vấn đề đặt ra.
4. Làm dữ liệu
Có một sự thật không thể chối cãi rằng việc làm dữ liệu là bước quan trọng nhất của mọi hệ thống AI. Bạn có thể sử dụng một mô hình đơn giản để giải quyết vấn đề miễn là bạn có một tập dữ liệu đủ tốt. Việc làm dữ liệu cũng thường ngôn của team bạn rất nhiều thời gian và tỉ mỉ. Bạn có thể nghiên cứu thật kĩ bài toán của mình và lựa chọn chiến lược làm dữ liệu cho phù hợp. Dưới đây là một số cách bạn có thể tham khảo:
- Tìm kiếm, xin hoặc mua các tập dữ liệu có sẵn với một số bài toán bạn vẫn có thể thực hiện bằng cách này tuy nhiên có một số nhược điểm đó là không phải lúc nào bạn cũng tìm ra được tập dữ liệu đúng với bài toán của mình, hoặc có thể tìm ra nhưng không dễ gì xin hoặc mua được.
- Tự tạo dữ liệu việc tự tạo dữ liệu giúp bạn kiểm soát được chất lượng của dữ liệu hơn và giúp chúng ta chủ động vào đúng domain mà yêu cầu bài toán đang hướng tới. Tuy nhiên công việc này cũng khiến cho chúng ta mất khá nhiều thời gian, bạn có thể thực hiện theo cách là làm trên toàn bộ dữ liệu hoặc làm trên một phần của dữ liệu rồi training mô hình để dự đoán phần dữ liệu còn lại sau đó validate lại dữ liệu đó. Tuỳ vào khối lượng công việc và độ lớn của nhân lực mà chúng ta lựa chọn chiến lược cho phù hợp nhưng dù làm theo cách nào đi chăng nữa thì bạn vẫn phải đảm bảo được sự chính xác của dữ liệu. Điều này là điểu quan trọng nhất.
5. Training các model
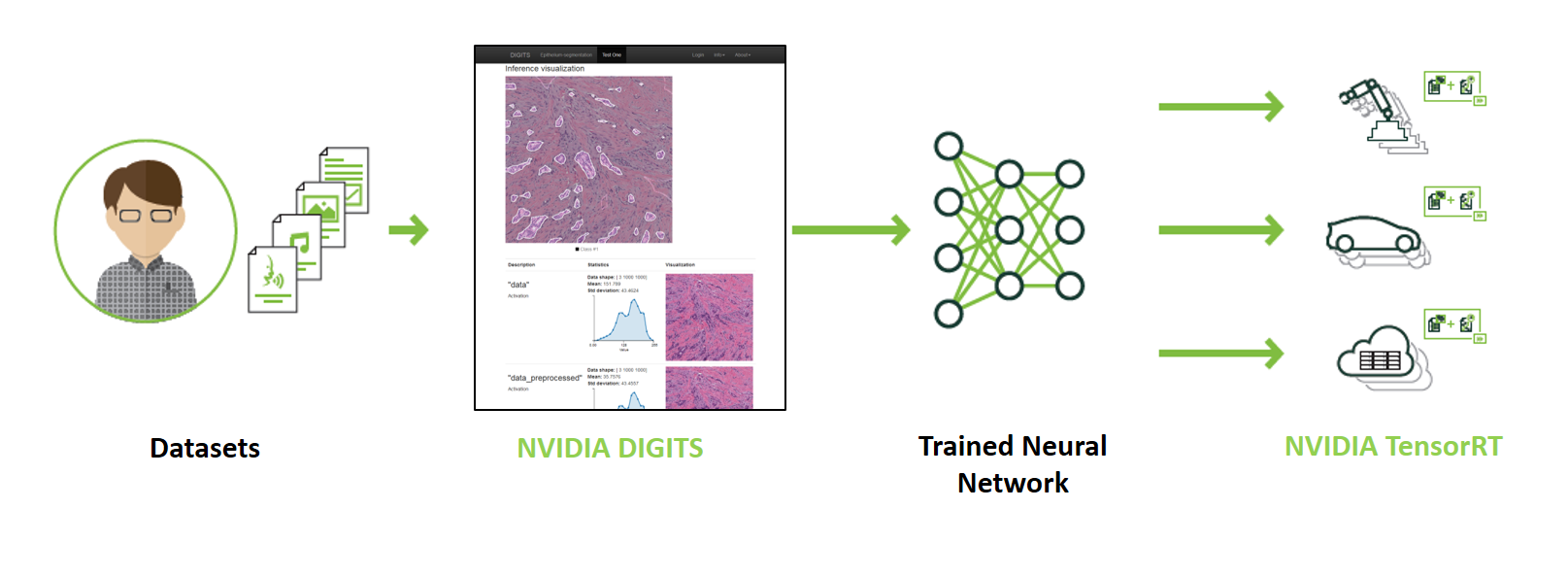
Sau khi lựa chọn các phương pháp training và thực hiện trên các tập dữ liệu thì việc cần làm tiếp theo đó là training các mô hình. Rất nhiều bạn coi đây là một bước quan trọng nhất nhưng quên mất rằng bước này chỉ trở nên quan trọng nhất nếu như bạn đã làm tốt các bước phía trên. Việc training các mô hình tuỳ thuộc vào bài toán nhưng vẫn có thể có một vài quy tắc chung cho nó. Dưới đây là một vài quy tắc mà bạn có thể áp dụng trong dự án của mình:
-
Nếu có thể hãy thử transfer learning trước với các bài toán của bạn nếu tìm được các pretrained model thì lời khuyên là nên thử nghiệm chúng với phương pháp transfer learning trước. Điều này khiến cho thời gian để validate được kết quả trở nên nhanh chóng hơn nữa việc transfer từ một mô hình pretrained thường đem lại kết quả tốt hơn và thời gian training thường là nhanh hơn so với việc training cùng một mô hình đó nhưng các tham số được khởi tạo từ đầu.
-
Hạn chế tối đa việc phụ thuộc qua lại giữa các mô hình việc phụ thuộc qua lại giữa các mô hình là điều không thể tránh khỏi trong một dự án lớn. Sau một hồi làm survey bạn đưa ra một thiết kế tổng quan cho hệ thống như sau:
- Step 1: Phân loại giấy tờ một mô hình classification được sử dụng để tự động nhận dạng loại giấy tờ tuỳ thân của bạn. Độ chính xác là 95%
- Step 2: Crop giấy tờ một mô hình sử dụng để crop và align lại giấy tờ với độ chính xác là 98%
- Step 3: Extract các thông tin một mô hình object detection được sử dụng để extract thông tin từ giấy tờ đó với độ chính xác 90%
- Step 4: OCR một mô hình nhận dạng chữ in được sử dụng để nhận dạng chữ trong giấy tờ với độ chính xác là 90%
-
Cân bằng giữa độ chính xác và tốc độ việc điều chỉnh cân bằng giữa độ chính xác và tốc độ là một điều cần cân nhắc khi lựa chọn training các mô hình, tuỳ thuộc vào yêu cầu bài toán của bạn mà lựa chọn training một mô hình cho phù hợp.
-
Phải cân nhắc đến bước deploy điều này cần được làm rõ và cân nhắc kĩ trước khi training, giúp bạn có một tư duy tìm hiểu trước về môi trường deploy trước khi tiến hành training mô hình.
6. Đánh giá các mô hình
Việc đánh giá các mô hình cần phải được quy định trong nội bộ của team và đảm bảo các yếu tố sau:
- Xây dựng tập dữ liệu test chuẩn chỉnh dữ liệu test phải đảm bảo cover được tối đa các trường hợp có thể gặp được trong thực tế. Phải được xây dựng tỉ mỉ và độc lập với quá trình trianing mô hình.
- Độc lập hoàn toàn dữ liệu test Dữ liệu test là độc lập hoàn toàn và không thể sử dụng trực tiếp hoặc gián tiếp (tạo ra các biến thể rất nhỏ) trong bước training mô hình. Việc phân chia bộ test có thể sử dụng chung cho cả team để đảm bảo tính khách quan giữa các model. Việc test trên tập test là một bước khá quan trọng để đánh giá môt mô hình có thực sự tốt và có thể sử dụng trên thực tế hay không.
- Luôn sử dụng Confusion Matrix cho phân lớp điều này giúp cho mô hình phân lớp được đánh giá khách quan hơn và giúp chúng ta tìm ra được các đặc trưng của từng model. Ví dụ model A dự đoán tốt hơn cho class 1, model B dự đoán tốt hơn cho class 2 …. và điều đó rất thuận lợi cho quá trình ensemble các mô hình sau này.

- End users is the best kể cả việc test trên tập test có thể giúp bạn nghiệm thu được application đối với khách hàng thì cũng không có gì khẳng định được mô hình của bạn sẽ chạy tốt tương tự trên thực tế. Luôn luôn có hệ thống lắng nghe feedback từ phía user để tìm ra được các hướng improve cho bài toán của mình.
7. Deploy hệ thống
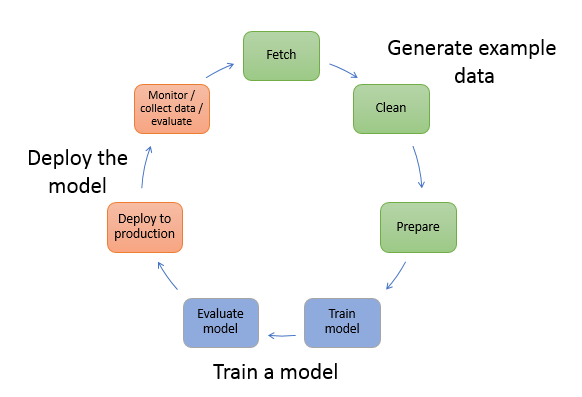
Sau tất cả, mục đích cuối cùng mà người dùng mong muốn là được trải nghiệm một sản phẩm AI trên thực tế mà không cần mất quá nhiều kĩ thuật. Đó chính là bước chúng ta deploy mô hình. Việc deploy một hệ thống mô hình AI cũng không khác quá nhiều so với các hệ thống khác nó vẫn phải đảm bảo được các yếu tố cốt lõi:
- Hạn chế tối đa down time trong quá trình deploy thì việc có xảy ra down-time là điều không thể tránh khỏi nên tất cá các phương pháp deploy của chúng ta cũng như việc cập nhật mô hình phải đảm bảo được hạn chế tối đa thời gian đó. Điều này cũng đồng nghĩa với việc service của chúng ta có thể hoạt động được tối đa thời gian của nó.
- Phải cân nhắc đến thời gian predict là một trong những yếu tốt khá quan trọng trong đa số các bài toán hiện tại khi mà mục tiêu real time đang được rất nhiều ứng dụng quan tâm đến.
- Phải có hệ thống lưu trữ lại dữ liệu và kết qủa của mô hình việc theo dõi được két quả của mô hình giúp chúng ta lên kế hoạch phù hợp để update mô hình cho phù hợp.
- Khả năng scale dễ dàng việc deploy phải đảm bảo được sao cho việc scale up hệ thống trở nên dễ dàng hơn và đảm bảo tối đa các rủi ro trong quá trình scale up. Điều này giúp cho ứng dụng của chúng ta có khả năng mở rộng trong mọi điều kiện và hoàn cảnh.
Kết luận
Qua bài viết này Hybrid Technolgies hy vọng có thể đem đến cho các bạn một cái nhìn tổng quan khi thực hiện một project liên quan đến AI trong thực tế. Đó không phải là những gì đó quá hàn lâm nhưng gần gũi với các anh em làm kĩ thuật. Hãy comment những ý kiến đóng góp của các bạn nhé!